
[ad_1]
In current months, quite a few Transformer fashions have emerged in AI, every with distinctive and typically amusing names. Nonetheless, these names may not present a lot perception into what these fashions really do. This text goals to supply a complete and simple listing of the most well-liked Transformer fashions. It should classify these fashions and likewise introduce vital elements and improvements throughout the Transformer household. The highest listing will cowl fashions educated by way of self-supervised studying, like BERT or GPT-3, in addition to fashions that endure further coaching with human involvement, such because the InstructGPT mannequin utilized by ChatGPT.

What are Transformers in AI?
Transformers are a sort of deep studying fashions that had been launched in a analysis paper known as “Consideration is All you Want” by Google researchers in 2017. This paper has gained immense recognition, accumulating over 38,000 citations in simply 5 years.
The unique Transformer structure is a particular type of encoder-decoder fashions that had gained reputation previous to its introduction. These fashions predominantly relied on LSTM and different variations of Recurrent Neural Networks (RNNs), with consideration being simply one of many mechanisms utilized. Nonetheless, the Transformer paper proposed a revolutionary thought that focus might function the only real mechanism to determine dependencies between enter and output.
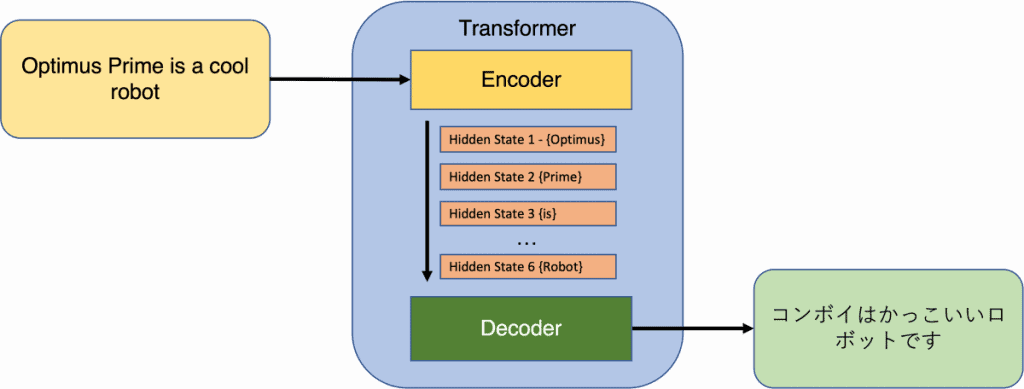
Within the context of Transformers, the enter consists of a sequence of tokens, which will be phrases or subwords in pure language processing (NLP). Subwords are generally employed in NLP fashions to deal with the problem of out-of-vocabulary phrases. The output of the encoder produces a fixed-dimensional illustration for every token, together with a separate embedding for your complete sequence. The decoder takes the encoder’s output and generates a sequence of tokens as its output.
Because the publication of the Transformer paper, common fashions like BERT and GPT have adopted elements of the unique structure, both utilizing the encoder or decoder elements. The important thing similarity between these fashions lies within the layer structure, which includes self-attention mechanisms and feed-forward layers. In Transformers, every enter token traverses its personal path by way of the layers whereas sustaining direct dependencies with each different token within the enter sequence. This distinctive function permits for parallel and environment friendly computation of contextual token representations, a functionality not possible with sequential fashions like RNNs.
Whereas this text solely scratches the floor of the Transformer structure, it offers a glimpse into its elementary elements. For a extra complete understanding, we suggest referring to the unique analysis paper or The Illustrated Transformer put up.
What are Encoders and Decoders in AI?
Think about you’ve gotten two fashions, an encoder and a decoder, working collectively like a crew. The encoder takes an enter and turns it right into a fixed-length vector. Then, the decoder takes that vector and transforms it into an output sequence. These fashions are educated collectively to ensure the output matches the enter as carefully as attainable.
Each the encoder and decoder had a number of layers. Every layer within the encoder had two sub layers: a multi-head self-attention layer and a easy feed ahead community. The self-attention layer helps every token within the enter perceive the relationships with all the opposite tokens. These sublayers even have a residual connection and a layer normalization to make the training course of smoother.
The decoder’s multi-head self-attention layer works a bit in another way from the one within the encoder. It masks the tokens to the suitable of the token it’s specializing in. This ensures that the decoder solely appears on the tokens that come earlier than the one it’s making an attempt to foretell. This masked multi-head consideration helps the decoder generate correct predictions. Moreover, the decoder contains one other sublayer, which is a multi-head consideration layer over all of the outputs from the encoder.
It’s vital to notice that these particular particulars have been modified in several variations of the Transformer mannequin. Fashions like BERT and GPT, for instance, are primarily based on both the encoder or decoder facet of the unique structure.
What are Consideration Layers in AI?
Within the mannequin structure we mentioned earlier, the multi-head consideration layers are the particular parts that make it highly effective. However what precisely is consideration? Consider it as a perform that maps a query to a set of knowledge and offers an output. Every token within the enter has a question, key, and worth related to it. The output illustration of every token is calculated by taking a weighted sum of the values, the place the load for every worth is set by how effectively it matches the question.
Transformers use a compatibility perform known as scaled dot product to compute these weights. The fascinating factor about consideration in Transformers is that every token goes by way of its personal calculation path, permitting for parallel computation of all of the tokens within the enter sequence. It’s merely a number of consideration blocks that independently calculate representations for every token. These representations are then mixed to create the ultimate illustration of the token.
In comparison with different forms of networks like recurrent and convolutional networks, consideration layers have a number of benefits. They’re computationally environment friendly, which means they’ll course of data shortly. In addition they have larger connectivity, which is useful for capturing long-term relationships in sequences.
What are Positive-tuned Fashions in AI?
Basis fashions are highly effective fashions which can be educated on a considerable amount of normal knowledge. They’ll then be tailored or fine-tuned for particular duties by coaching them on a smaller set of target-specific knowledge. This strategy, popularized by the BERT paper, has led to the dominance of Transformer-based fashions in language-related machine studying duties.
Within the case of fashions like BERT, they produce representations of enter tokens however don’t accomplish particular duties on their very own. To make them helpful, further neural layers are added on high and the mannequin is educated end-to-end, a course of referred to as fine-tuning. Nonetheless, with generative fashions like GPT, the strategy is barely totally different. GPT is a decoder language mannequin educated to foretell the subsequent phrase in a sentence. By coaching on huge quantities of net knowledge, GPT can generate cheap outputs primarily based on enter queries or prompts.
To make GPT extra useful, OpenAI researchers developed InstructGPT, which is educated to observe human directions. That is achieved by fine-tuning GPT utilizing human-labeled knowledge from numerous duties. InstructGPT is able to performing a variety of duties and is utilized by common engines like ChatGPT.
Positive-tuning can be used to create variants of basis fashions optimized for particular functions past language modeling. For instance, there are fashions fine-tuned for semantic-related duties like textual content classification and search retrieval. Moreover, transformer encoders have been efficiently fine-tuned inside multi-task studying frameworks to carry out a number of semantic duties utilizing a single shared mannequin.
As we speak, fine-tuning is used to create variations of basis fashions that can be utilized by a lot of customers. The method entails producing responses to enter prompts and having people rank the outcomes. This rating is used to coach a reward mannequin, which assigns scores to every output. Reinforcement studying with human suggestions is then employed to additional prepare the mannequin.
Why are Transformers the way forward for AI?
Transformers, a sort of highly effective mannequin, had been first demonstrated within the subject of language translation. Nonetheless, researchers shortly realized that Transformers could possibly be used for numerous language-related duties by coaching them on a considerable amount of unlabeled textual content after which fine-tuning them on a smaller set of labeled knowledge. This strategy allowed Transformers to seize important information about language.
The Transformer structure, initially designed for language duties, has additionally been utilized to different purposes like producing pictures, audio, music, and even actions. This has made Transformers a key element within the subject of Generative AI, which is change numerous elements of society.
The provision of instruments and frameworks comparable to PyTorch and TensorFlow has performed a vital position within the widespread adoption of Transformer fashions. Corporations like Huggingface have constructed their enterprise across the thought of commercializing open-source Transformer libraries, and specialised {hardware} like NVIDIA’s Hopper Tensor Cores has additional accelerated the coaching and inference velocity of those fashions.
One notable utility of Transformers is ChatGPT, a chatbot launched by OpenAI. It turned extremely common, reaching thousands and thousands of customers in a brief interval. OpenAI has additionally introduced the discharge of GPT-4, a extra highly effective model able to attaining human-like efficiency in duties comparable to medical and authorized exams.
The affect of Transformers within the subject of AI and their big selection of purposes is simple. They’ve remodeled the way in which we strategy language-related duties and are paving the way in which for brand spanking new developments in generative AI.
3 Sorts of Pretraining Architectures
The Transformer structure, initially consisting of an Encoder and a Decoder, has advanced to incorporate totally different variations primarily based on particular wants. Let’s break down these variations in easy phrases.
Encoder Pretraining: These fashions give attention to understanding full sentences or passages. Throughout pretraining, the encoder is used to reconstruct masked tokens within the enter sentence. This helps the mannequin be taught to grasp the general context. Such fashions are helpful for duties like textual content classification, entailment, and extractive query answering.Decoder Pretraining: Decoder fashions are educated to generate the subsequent token primarily based on the earlier sequence of tokens. They’re referred to as auto-regressive language fashions. The self-attention layers within the decoder can solely entry tokens earlier than a given token within the sentence. These fashions are perfect for duties involving textual content era.Transformer (Encoder-Decoder) Pretraining: This variation combines each the encoder and decoder elements. The encoder’s self-attention layers can entry all enter tokens, whereas the decoder’s self-attention layers can solely entry tokens earlier than a given token. This structure allows the decoder to make use of the representations realized by the encoder. Encoder-decoder fashions are well-suited for duties like summarization, translation, or generative query answering.
Pretraining targets can contain denoising or causal language modeling. These targets are extra complicated for encoder-decoder fashions in comparison with encoder-only or decoder-only fashions. The Transformer structure has totally different variations relying on the main focus of the mannequin. Whether or not it’s understanding full sentences, producing textual content, or combining each for numerous duties, Transformers provide flexibility in addressing totally different language-related challenges.
8 Sorts of Duties for Pre-trained Fashions
When coaching a mannequin, we have to give it a process or goal to be taught from. There are numerous duties in pure language processing (NLP) that can be utilized for pretraining fashions. Let’s break down a few of these duties in easy phrases:
Language Modeling (LM): The mannequin predicts the subsequent token in a sentence. It learns to grasp the context and generate coherent sentences.Causal Language Modeling: The mannequin predicts the subsequent token in a textual content sequence, following a left-to-right order. It’s like a storytelling mannequin that generates sentences one phrase at a time.Prefix Language Modeling: The mannequin separates a ‘prefix’ part from the principle sequence. It might probably attend to any token throughout the prefix, after which generates the remainder of the sequence autoregressively.Masked Language Modeling (MLM): Some tokens within the enter sentences are masked, and the mannequin predicts the lacking tokens primarily based on the encircling context. It learns to fill within the blanks.Permuted Language Modeling (PLM): The mannequin predicts the subsequent token primarily based on a random permutation of the enter sequence. It learns to deal with totally different orders of tokens.Denoising Autoencoder (DAE): The mannequin takes {a partially} corrupted enter and goals to get better the unique, undistorted enter. It learns to deal with noise or lacking components of the textual content.Changed Token Detection (RTD): The mannequin detects whether or not a token comes from the unique textual content or a generated model. It learns to establish changed or manipulated tokens.Subsequent Sentence Prediction (NSP): The mannequin learns to tell apart whether or not two enter sentences are steady segments from the coaching knowledge. It understands the connection between sentences.
These duties assist the mannequin be taught the construction and which means of language. By pretraining on these duties, fashions achieve a great understanding of language earlier than being fine-tuned for particular purposes.
High 30+ Transformers in AI
FAQs
What are Transformers in AI?
Transformers in AI are a sort of deep studying structure that has modified pure language processing and different duties. They use self-attention mechanisms to seize relationships between phrases in a sentence, enabling them to grasp and generate human-like textual content.
What are Encoders and Decoders in AI?
Encoders and decoders are elements generally utilized in sequence-to-sequence fashions. Encoders course of enter knowledge, comparable to textual content or pictures, and convert it right into a compressed illustration, whereas decoders generate output knowledge primarily based on the encoded illustration, enabling duties like language translation or picture captioning.
What are Consideration Layers in AI?
Consideration layers are elements utilized in neural networks, notably in Transformer fashions. They allow the mannequin to selectively give attention to totally different components of the enter sequence, assigning weights to every ingredient primarily based on its relevance, permitting for capturing dependencies and relationships between parts successfully.
What are Positive-tuned Fashions in AI?
Positive-tuned fashions consult with pre-trained fashions which were additional educated on a particular process or dataset to enhance their efficiency and adapt them to the particular necessities of that process. This fine-tuning course of entails adjusting the parameters of the mannequin to optimize its predictions and make it extra specialised for the goal process.
Why are Transformer Fashions the way forward for AI?
Transformers are thought-about the way forward for AI as a result of they’ve demonstrated distinctive efficiency in a variety of duties, together with pure language processing, picture era, and extra. Their skill to seize long-range dependencies and course of sequential knowledge effectively makes them extremely adaptable and efficient for numerous purposes, paving the way in which for developments in generative AI and revolutionizing many elements of society.
What Are the Most Well-known Transformer Fashions in AI?
Essentially the most well-known transformer fashions in AI embrace BERT (Bidirectional Encoder Representations from Transformers), GPT (Generative Pre-trained Transformer), and T5 (Textual content-to-Textual content Switch Transformer). These fashions have achieved exceptional leads to numerous pure language processing duties and have gained important reputation within the AI analysis neighborhood.
Learn extra about AI:
[ad_2]
Source link


