
[ad_1]

Stability AI has unveiled a preview of a brand new mannequin referred to as SDXL Beta, quick for Secure Diffusion XL Beta. Up to now, the corporate hasn’t shared lots of details about the mannequin, however it’s out there for testing for anybody who desires to take action. What’s novel about this SDXL mannequin for steady diffusion? What are its benefits and drawbacks? Let’s examine.

What precisely is the SDXL mannequin?
The SDXL mannequin is a brand new mannequin that’s at the moment being educated. It’s removed from being completed, and by the point it’s launched, lots of particulars about it could change; for all we all know, it could not even be referred to as the SDXL mannequin. All we all know is that it’s a bigger mannequin with extra parameters and a few unknown enhancements. It’s a v2 mannequin, not a v3 mannequin (no matter meaning). It’s doable that the enhancements within the v2 mannequin might enhance the system’s efficiency, however with out additional data, it’s tough to find out how vital these enhancements could also be. Moreover, it might be useful to know what particular parameters have been added or adjusted on this model.
The SDXL mannequin is at the moment out there at DreamStudio, Stability AI’s official picture generator. Choose SDXL Beta from the mannequin menu to test it out. It appears to make use of superior algorithms and deep studying methods to create gorgeous visuals which can be excellent for a variety of purposes.
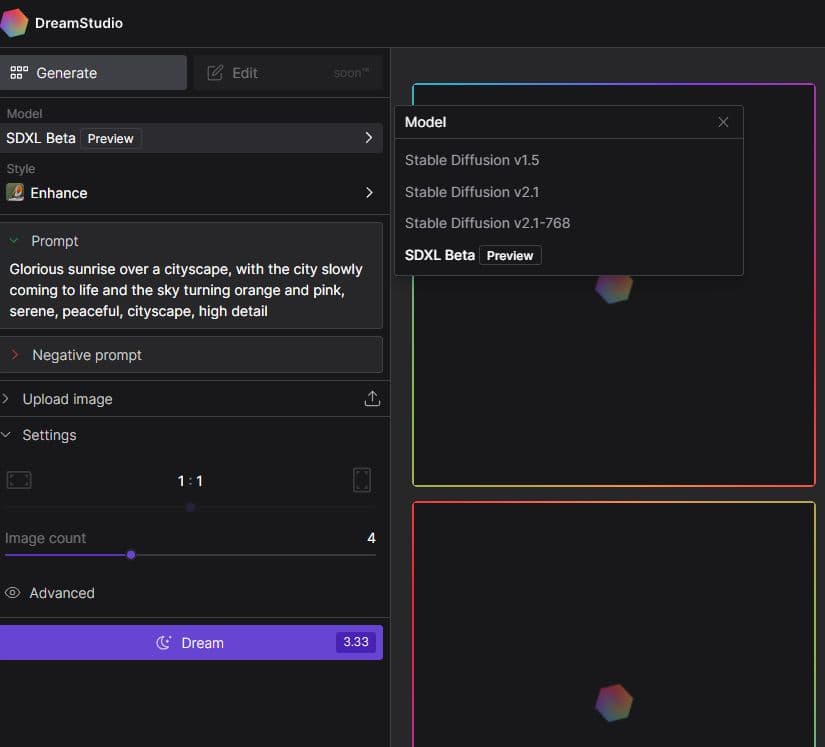
Enhancements
Legible textual content. SDXL is able to producing legible textual content and it’s most likely its most hanging function because it wasn’t doable within the present v1 and v2.1 fashions. SDXL’s generated textual content is just not at all times correct as you’ll be able to see within the Secure Diffusion Textual content under. Nevertheless, it’s far superior to v2.1, not to mention v1 mannequin. It’s because SDXLs makes use of a extra superior deep studying algorithm that permits it to know and generate extra advanced language constructions. With additional growth, it has the potential to grow to be much more correct and dependable.



Human anatomy. The correct technology of anatomically appropriate human figures has lengthy been a problem for steady diffusion. The presence of further or lacking limbs is frequent. Inpainting is often used to repair them, or, extra just lately, you should utilize ControlNet’s Open Pose function to duplicate a pose from a reference picture. We’re glad to notice that right here is the place the SDXL Beta mannequin has improved. The SDXL Beta mannequin has proven vital enchancment in precisely duplicating poses from reference pictures. This is usually a priceless instrument for varied purposes reminiscent of animation and digital actuality.



Portrait fashion. SDXL Beta produces wonderful portraits that appear like pictures – it’s an improve in comparison with model 1.5. The improved algorithm in SDXL Beta enhances the small print and coloration accuracy of the portraits, leading to a extra pure and real looking look. Customers also can alter the degrees of sharpness and saturation to attain their desired results.



Duotone. The key phrase duotone at all times produces black-and-white pictures within the v1.5 mannequin. Nevertheless, now, the duotone pictures produced by SDXL Beta are available in quite a lot of colours. It’s clear that in comparison with v1 fashions, the power to interpret the immediate has improved, leading to extra correct and related responses from the v2 fashions, making them a extra dependable instrument for pure language processing duties.



Creative kinds. There have been some minor changes, but it surely’s tough to find out whether or not the brand new mannequin offers higher outcomes as they’re merely distinctive. It’s doable that these changes might be a matter of private desire or subjective opinion, making it tough to make a definitive judgment on their high quality. Nonetheless, the individuality of the changes could also be noteworthy and value exploring additional.




Conclusion
Secure Diffusion can lastly produce textual content that is sensible.SDXL offers extra aesthetically pleasing pictures than the v2.1 and (to a lesser extent) the v1.5 fashions.The brand new mannequin produces pictures which can be extra correct.Human anatomy has improved.Unfavourable prompts will not be as vital as in v2.1.It might probably create real looking portaits. Some oddities within the mannequin can be mounted earlier than launch.
Learn extra associated articles:
[ad_2]
Source link


