
[ad_1]


Understanding how you can interpret and describe visible content material is important for a variety of functions, from e-commerce to social media. Enter MiniGPT-4, the newest AI mannequin that mixes the ability of visible processing with cutting-edge language understanding.
MiniGPT-4 employs a frozen visible encoder and a big language mannequin, related by means of a single projection layer, to generate correct picture descriptions, write tales and poems based mostly on photos, present options to issues depicted in footage, and even educate customers how you can prepare dinner based mostly on meals photographs.
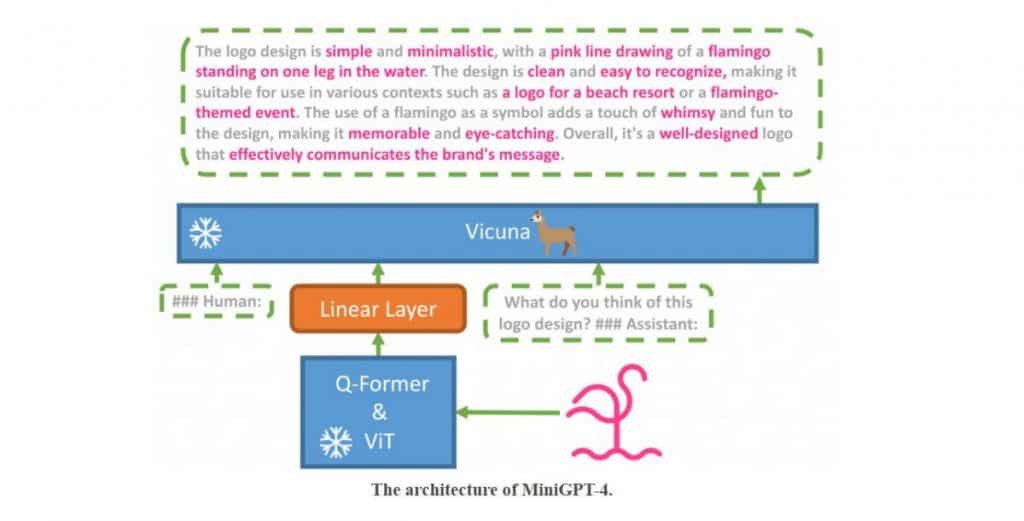
The mannequin is very environment friendly, requiring solely the alignment of 5 million image-text pairs to coach the linear layer that aligns visible options with the frozen massive language mannequin, Vicuna.
Vicuna is constructed upon LLaMA and may carry out complicated linguistic duties. GPT-4, the newest Massive Language Mannequin from OpenAI, powers MiniGPT-4. The multimodal nature of GPT-4 units it aside from its predecessors, making it appropriate for numerous functions, together with video video games, Chrome extensions, and complicated reasoning questions.
MiniGPT-4 has proven related talents to GPT-4, corresponding to producing detailed picture descriptions and creating web sites from hand-written drafts. To enhance the mannequin’s language output, a greater dataset was curated for additional fine-tuning utilizing a conversational template. This resulted in higher language era with improved reliability and general usability.
The mannequin’s distinctive capabilities stem from its two-stage coaching course of, which permits MiniGPT to generate correct and pure language descriptions of photos. Through the first stage, MiniGPT-4 is educated on tens of millions of image-text pairs, as talked about above, permitting it to study objects, folks, and locations and describe them in phrases. This pre-training takes about 10 hours and requires 4 A100 (80GB) GPUs. The output of this stage is generated by the imaginative and prescient transformer based mostly on the enter picture.
Nevertheless, the primary stage of pre-training can produce outputs that lack coherence, corresponding to repetitive phrases, fragmented sentences, or irrelevant content material. To deal with this difficulty, MiniGPT-4 undergoes a second stage of coaching, the place a smaller however high-quality dataset of image-text pairs is used to fine-tune the mannequin’s textual content descriptions to be extra correct and pure.
From producing web site layouts to offering options to issues depicted in photos, MiniGPT-4 is a powerful step ahead on the earth of AI, and it’s solely the start.
Learn extra:
[ad_2]
Source link


