
[ad_1]

Otter is a cutting-edge visible language mannequin (VLM) constructed on the OpenFlamingo platform, and it’s set to enhance the way in which we work together with visible content material. As a part of the bold Otter challenge, Microsoft has launched an enormous instructive visual-text dataset known as MIMIC-IT. This dataset comprises a staggering 2.8 million pairs of linked multimodal directions with solutions, together with 2.2 million distinctive directions derived from pictures and movies. The dataset was meticulously curated to simulate pure dialogues, overlaying eventualities equivalent to picture and video descriptions, picture comparisons, question-answering, scene understanding, and extra. These high-quality instruction-response pairs had been generated utilizing the highly effective ChatGPT-0301 API, representing an funding of roughly $20k.

The MIMIC-IT dataset performs an important function in coaching the Otter mannequin, which has been designed to excel in understanding visible scenes, reasoning, and logical conclusions. Every instruction-response pair within the dataset is accompanied by multi-modal in-context info, creating conversational contexts that empower the mannequin to know the nuances of notion, reasoning, and planning. To scale the annotation course of, Microsoft employed an computerized annotation pipeline named Syphus, which mixes human experience with the capabilities of GPT to make sure the dataset’s high quality and variety.
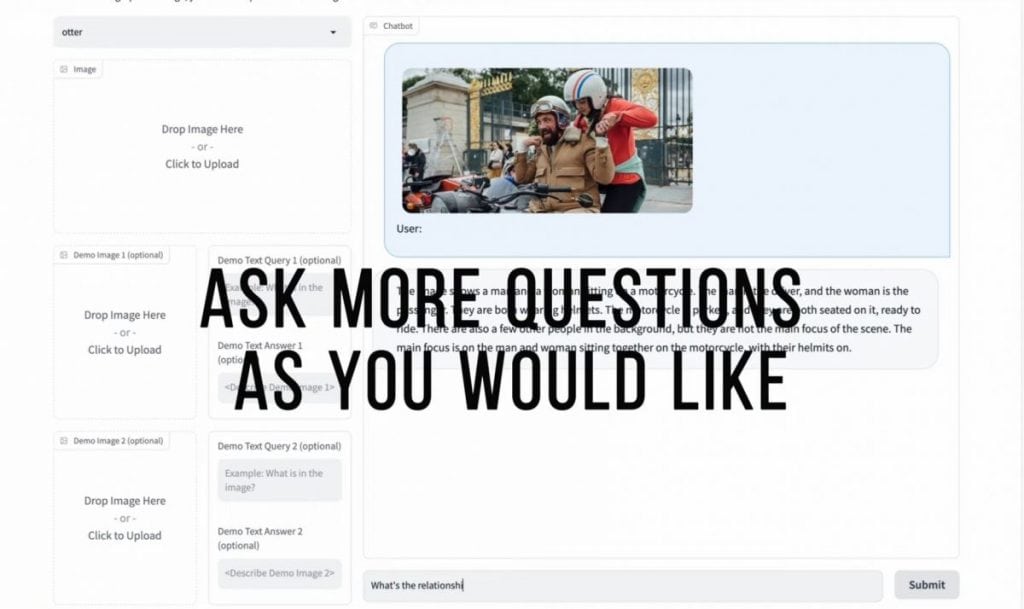
Utilizing the MIMIC-IT dataset, Microsoft educated the Otter mannequin, a large-scale VLM primarily based on the OpenFlamingo platform. By means of in depth evaluations on vision-language benchmarks, Otter has demonstrated outstanding proficiency in multi-modal notion, reasoning, and in-context studying. Human evaluations have revealed its means to successfully align with the consumer’s intentions, making it a useful device for decoding and executing complicated duties primarily based on pure language directions.
Otter v0.2 has expanded its capabilities to help video inputs, permitting it to course of frames and a number of pictures as in-context examples.
The discharge of the MIMIC-IT dataset, together with the instruction-response assortment pipeline, benchmarks, and the Otter mannequin, represents a major milestone within the area of multimodal language processing. By making these assets obtainable to researchers and builders, Microsoft goals to foster innovation and collaboration, enabling the combination of Otter and OpenFlamingo into personalized coaching and inference pipelines utilizing the favored Hugging Face Transformers framework.
The MIMIC-IT dataset encompasses a variety of real-life eventualities, empowering Imaginative and prescient-Language Fashions (VLMs) to understand basic scenes, cause about context, and intelligently differentiate between observations. This opens up prospects, equivalent to the event of selfish visible assistant fashions that may reply questions like, “Hey, do you suppose I left my keys on the desk?”.
MIMIC-IT is just not restricted to the English language. It additionally helps a number of languages, together with Chinese language, Korean, Japanese, German, French, Spanish, and Arabic. This multilingual help permits a bigger international viewers to learn from the comfort and developments led to by AI.
To make sure the technology of high-quality instruction-response pairs, Microsoft has launched Syphus, an automatic pipeline that includes system messages, visible annotations, and in-context examples as prompts for ChatGPT. This ensures the reliability and accuracy of the generated instruction-response pairs throughout a number of languages.
Learn extra about AI:
[ad_2]
Source link


