
[ad_1]

There are two most important areas of LLM customization: fine-tuning (or further coaching) the pre-trained base mannequin and in-context studying. Fantastic-tuning requires important computing assets, knowledge assortment, and infrastructure to do that after which host fine-tuned fashions. In the meantime, in-context studying includes compiling the best immediate with examples of fixing the issue, akin to Chain-of-Thought (CoT). Nevertheless, there are some difficulties, such because the restricted dimension of the textual content that may be submitted to the mannequin and the truth that in a posh multi-pass immediate, the steps can intervene with one another, and the mannequin may be distracted by one thing that shouldn’t be distracted for the time being. The authors suggest another path referred to as LLM Applications, which may be thought of as the event of in-context studying.

LLM is constructed into this system (in a traditional programming language, for instance, in Python). This exterior code is answerable for storing the state and sustaining the mannequin step-by-step. It has a couple of main benefits: Programming languages are tailored for this, the dimensions of the accessible context grows, and the steps don’t intervene with each other. The important thing to fixing an issue by means of the LLM Program is the flexibility to decompose the answer to an issue right into a sequence of easier steps. This strategy differs from earlier works, the place the mannequin used exterior instruments akin to calculators or code interpreters to keep up the state. This strategy is sweet as a result of it’s doable to explain a posh and spreading process on this approach, making it simpler to check, debug, and consider high quality.
Moreover, there isn’t a interference between the steps, making it simpler to work with LLM. Query-answer techniques should not new both; they’ve existed lengthy earlier than LLMs. How is the duty of answering questions solved now?
Websites are up to date often, so a frozen mannequin shouldn’t be an choice; it should shortly develop into outdated and will be unable to reply questions on new merchandise. Fixed retraining of the mannequin for every replace shouldn’t be a practical choice: It’s costly and time-consuming. As a substitute, a web site’s pages are normally listed, put in some type of database, and infrequently vectored. At a person’s request, related paperwork are pulled up and despatched as a context to LLM.
In such a paradigm, the issue is of course solved by means of the LLM Program. As a bonus, it turns into doable to implement extra complicated multi-pass logic that may not match completely into the context.
Examined on the StrategyQA dataset containing binary classification issues, the answer of which includes multi-way reasoning. Like “Does daylight penetrate into the deepest place of the Black Sea?”. To reply, it’s essential discover the utmost depth (2 km) and the way deep gentle penetrates water (1 km), after which draw a conclusion. Let’s take a look at one other instance query: “Did Aristotle use a laptop computer?” This query shouldn’t be as simple and doesn’t observe the sequence of reasoning steps explicitly as “Was Aristotle alive when the laptop computer was invented?” does. The dataset focuses on questions the place such a sequence is implicit. There are solely 2,780 questions within the dataset, of which solely 918 have paragraphs with proof that reinforce all of the steps of the reasoning. In present work, it limits to this subset; in any other case, we must depend on LLM studying some info throughout pretraining.
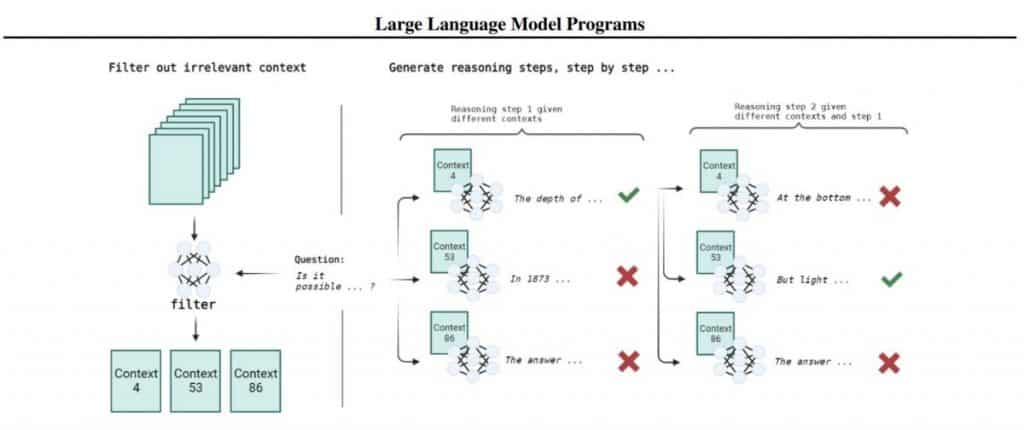
The OPT-175B LLM, by default, shouldn’t be superb at following directions; it didn’t must finetune directions nor on conversational knowledge. To resolve the evidence-supported question-answering downside, is split into a knowledge filtering stage and a tree search stage.
On the filtering stage, having a query, builders undergo all of the paragraphs and choose essentially the most related ones. For instance, with a few-shot immediate, ask the LLM to reply (sure/no) whether or not a given paragraph is related to the query requested. Examined on a 300 subset of StrategyQA, the place every query was matched with a paragraph, related or not, 50/50. OPT-175B and text-davinci-002 don’t have a a lot increased high quality than a random baseline: as much as 56%. The extra superior 11B Tk-Instruct shouldn’t be a lot better at 61.6%.
As a result of poor high quality of this strategy, another was put collectively that considers the typical damaging log-likelihood (NLL) of the query together with the previous paragraph of textual content after which ranks the outcomes. Evaluated on a dataset the place for every query, there have been 100 paragraphs, and just one was related (so random guessing provides 1%). We bought top-1 accuracy at 79% and top-5 at 93%. For this calculation, you normally want entry to the mannequin itself, which isn’t all the time accomplished within the API.
Subsequent comes the stage of constructing output chains. That is accomplished by means of a search by means of a tree the place the query is the basis, and at every stage, there are lots of paragraphs with doable proof used as context to generate the following step. Every path by means of the tree is a possible output chain. It’s unrealistic to attract a conclusion on all doable chains, so all accessible chains are ranked, and the highest-ranking chain is expanded. That is such a variation of beam search. The method stops when a response is made or the utmost allowed variety of steps has handed.
A very powerful particulars are the 2 rating methods examined for the tree search step. The primary technique relies on the typical NLL of your entire chain, whereas the second technique seems to be on the common distinction in NLL with and and not using a paragraph (P), with and with out query (Q). On the accessible 918 questions from StrategyQA, this strategy considerably improves the reply high quality relative to the baseline with CoT (60%); each search choices give round 66% (the technique with a barely increased delta). If golden info are submitted, the standard turns into round 81%, which is the higher restrict for OPT. Darklang appears to be going there someplace however in a barely totally different approach.
The article relies on the Telegram publish.
Learn extra about AI:
[ad_2]
Source link


