
[ad_1]
Google DeepMind investigated vision-language mannequin purposes, specializing in their potential for end-to-end robotic management. This investigation sought to find out whether or not these fashions had been able to broad generalisation. Moreover, it investigated whether or not sure cognitive capabilities, reminiscent of reasoning and planning, that are regularly related to expansive language fashions, might emerge on this context.

The elemental premise behind this exploration is intrinsically linked to the traits of enormous language fashions (LLMs). Such fashions are designed to generate any sequence able to encoding an unlimited vary of data. This consists of not simply widespread language or programming code like Python, but in addition particular instructions that may information robotic actions.
To place this into perspective, contemplate the mannequin’s capability to grasp and translate particular string sequences into actionable robotic instructions. As an illustration, a generated string reminiscent of “1 128 91 241 5 101 127 217” could be decoded within the following method:
The preliminary digit, one, signifies that the duty continues to be ongoing and has not reached completion.The following triad of numbers, 128-91-241, designates a relative and normalized shift throughout the three dimensions of house.The concluding set, 101-127-217, pinpoints the rotation diploma of the robotic’s useful arm phase.
Such a configuration allows the robotic to switch its state throughout six levels of freedom. Drawing a parallel, simply as language fashions assimilate basic concepts and ideas from huge textual information on the web, the RT-2 mannequin extracts information from web-based data to information robotic actions.
The potential implications of this are vital. If a mannequin is uncovered to a curated set of trajectories that basically point out, “to realize a specific final result, the robotic’s gripping mechanism wants to maneuver in a selected method,” then it stands to cause that the transformer might generate coherent actions according to this enter.
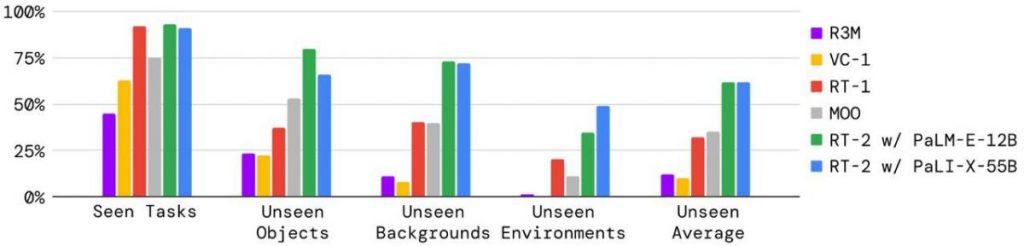
An important side beneath analysis was the capability to execute novel duties not lined throughout coaching. This may be examined in just a few distinct methods:
1) Unfamiliar Objects: Can the mannequin replicate a job when launched to things it hasn’t been skilled on? Success on this side hinges on changing the visible feed from the digicam right into a vector, which the language mannequin can interpret. The mannequin ought to then be capable of discern its that means, hyperlink a time period with its real-world counterpart, and subsequently information the robotic arm to behave accordingly.
2) Completely different Backgrounds: How does the mannequin reply when nearly all of the visible feed consists of recent components as a result of the backdrop of the duty’s location has been fully altered? As an example, a change in tables or perhaps a shift in lighting situations.
3) Assorted Environments: Extending the earlier level, what if the whole location itself is totally different?
For people, these eventualities appear easy – naturally, if somebody can discard a can of their room, they need to give you the chance to take action outside as properly, proper? (On a aspect observe, I’ve noticed just a few people in parks battling this seemingly easy job). But, for equipment, these are challenges that stay to be addressed.
Graphical information reveals that the RT-2 mannequin outperforms a few of its predecessors in the case of adapting to those new situations. This superiority largely stems from leveraging an expansive language mannequin, enriched by the plethora of texts it has processed throughout its coaching section.
One constraint highlighted by the researchers is the mannequin’s incapacity to adapt to completely new expertise. As an example, it wouldn’t comprehend lifting an object from its left or proper aspect if this hasn’t been a part of its coaching. In distinction, language fashions like ChatGPT have navigated this hurdle reasonably effortlessly. By processing huge quantities of knowledge throughout a myriad of duties, these fashions can swiftly decipher and act upon new requests, even when they’ve by no means encountered them earlier than.
Historically, robots have operated utilizing combos of intricate programs. In these setups, higher-level reasoning programs and foundational manipulation programs usually interacted with out environment friendly communication, akin to taking part in a recreation of “damaged telephone”. Think about conceptualizing an motion mentally, then needing to relay that to your physique for execution. The newly launched RT-2 mannequin streamlines this course of. It empowers a single language mannequin to undertake subtle reasoning whereas additionally dispatching direct instructions to the robotic. It demonstrates that with minimal coaching information, the robotic can perform actions it hasn’t explicitly discovered.
As an example, to allow older programs to discard waste, they required particular coaching to determine, choose up, and eliminate trash. In distinction, the RT-2 already possesses a elementary understanding of waste, can acknowledge it with out focused coaching, and might eliminate it even with out prior instruction on the motion. Think about the nuanced query, “what constitutes waste?” It is a difficult idea to formalize. A chip bag or banana peel transitions from being an merchandise to waste post-consumption. Such intricacies don’t want express rationalization or separate coaching; RT-2 deciphers them utilizing its inherent understanding and acts accordingly.
Right here’s why this development is pivotal and its future implications:
Language fashions, like RT-2, operate as all-encompassing cognitive engines. Their capability to generalize and switch information throughout domains means they’re adaptable to various purposes.The researchers deliberately didn’t make use of essentially the most superior fashions for his or her examine, aiming to make sure every mannequin responded inside a second (that means a robotic motion frequency of at the least 1 Hertz). Hypothetically, integrating a mannequin like GPT-4 and a superior visible mannequin might yield much more compelling outcomes.Complete information continues to be sparse. Nonetheless, transitioning from the present state to a holistic dataset, starting from manufacturing unit manufacturing traces to home chores, is projected to take about one to 2 years. It is a tentative estimate, so specialists within the discipline might supply extra precision. This inflow of knowledge will inevitably drive vital developments.Whereas the RT-2 was developed utilizing a selected approach, quite a few different strategies exist. The long run doubtless holds a fusion of those methodologies, additional enhancing robotic capabilities. One potential strategy might contain coaching robots utilizing movies of human actions. There’s no want for unique recordings – platforms like TikTok and YouTube supply an unlimited repository of such content material.
Learn extra about AI:
[ad_2]
Source link


