
[ad_1]

MIT researchers performed the experiment with the aim of evaluating GPT-4’s capabilities. They needed to know if GPT-4 would have the ability to graduate from their prestigious faculty and move the exams. The outcomes had been nothing in need of astounding, as GPT-4 displayed distinctive competence in a wide range of fields, together with engineering, legislation, and even historical past.

A collection of 30 programs overlaying a variety of subjects, from elementary algebra to topology, was made to make use of within the experiment. There have been an astounding 1,679 duties whole, which is the same as 4,550 distinct questions. The mannequin’s capabilities had been evaluated utilizing about 10% of those questions, and the remaining 90% served as supplemental info. The remaining questions had been both used as a database or to coach the fashions so as to discover the questions that had been most much like every check immediate.
The researchers employed a number of strategies to assist GPT-4 in answering the questions precisely. These methods included:
Chain of Reasoning: Prompting the mannequin to suppose step-by-step and categorical its ideas instantly inside the immediate.Coding Method: As an alternative of offering the ultimate answer, the mannequin was requested to put in writing code that may yield the reply.Critic Immediate: After offering a solution, a separate immediate (a complete of three distinctive prompts) was added to judge the answer, figuring out any errors and guiding the mannequin to offer the right reply. This course of might be repeated a number of occasions.Professional Prompting: A key technique concerned including a particular phrase at first of the immediate, designed to encourage GPT-4 to suppose like a selected particular person. As an illustration, phrases like “You might be an MIT Professor of Laptop Science and Arithmetic instructing Calculus” had been pre-generated by the mannequin, providing an informed guess concerning the three most succesful specialists to resolve the query.
The researchers then mixed these strategies into chains, typically utilizing a mixture of two or three prompts. The generated solutions had been completely examined, together with a singular analysis approach. GPT-4 was introduced with a process, the right reply, and the mannequin’s personal generated reply, and requested to find out if it was right or not.
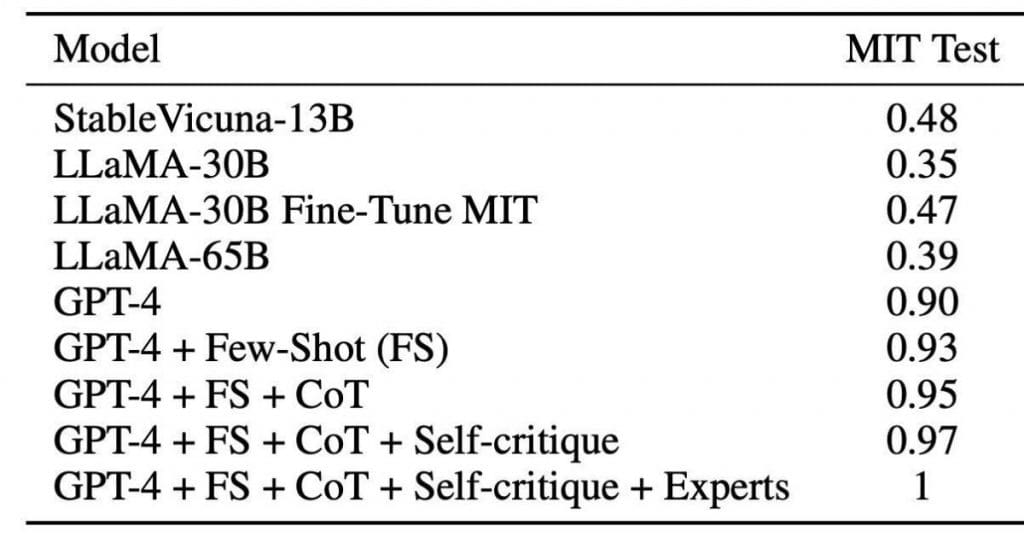
GPT-4 demonstrated a 90% success fee in fixing the reserved 10% of questions with out assistance from extra methods. Nevertheless, when using the aforementioned tips, the mannequin achieved a flawless 100% accuracy, flawlessly answering each query. In essence, GPT-4 proved itself able to flawlessly tackling each process, akin to “incomes” an MIT diploma.
The researchers’ work serves as a major step ahead, demonstrating the transformative energy of superior language fashions like GPT-4.
GPT-4 Hype: Essential Examination of the Mannequin’s Efficiency
Amidst the fervor surrounding the current article on GPT-4’s astounding success, a gaggle of researchers from MIT took a better have a look at the claims made and raised pertinent questions concerning the validity of the outcomes. They sought to find out if the assertion that GPT-4 achieved a flawless 100% accuracy in answering the check questions held true.
Upon cautious examination, it turned evident that the assertion of GPT-4’s excellent efficiency was not totally correct. Just a few essential factors got here to gentle, difficult the credibility of the findings.
Firstly, a notable concern arose concerning the analysis course of itself. The unique article talked about that the mannequin was given a process, together with the right reply, after which evaluated its personal generated response. This self-assessment method raises doubts concerning the objectivity of the analysis, as no exterior verification was performed. It’s important to validate the mannequin’s capability to judge options precisely, which was not addressed within the research.
Furthermore, some peculiarities emerged throughout additional investigation. As an illustration, it was found that sure questions had been repeated, and when the mannequin was prompted to seek for related questions, it successfully offered the right solutions. This method considerably boosted the mannequin’s efficiency however raised questions concerning the integrity of the analysis. An instance can be asking the mannequin to resolve the issue “2+2=?” after already mentioning that “3+4=7” and “2+2=4.” Naturally, the mannequin would possess the right reply.
Roughly 4% of the questions posed challenges for the language mannequin as they concerned diagrams and graphs. For the reason that mannequin relied solely on text-based enter, it was incapable of offering correct responses to such questions. Until the solutions had been explicitly current within the immediate, the mannequin struggled to deal with them successfully.
It was found that among the purported questions weren’t questions in any respect. As an alternative, they seemed to be introductory textual content or fragments of duties. This oversight in the course of the analysis course of resulted within the inclusion of irrelevant info within the set of questions.
One other crucial facet that was not addressed within the unique work was the lack of knowledge concerning the timeline or breakdown of the questions. It stays unclear whether or not GPT-4 had encountered these particular duties on the web or every other supply previous to the experiment. Even with out looking for related questions, the mannequin achieved a 90% success fee, which raises questions on potential exterior influences.
The aforementioned findings had been uncovered in just some hours of examination, specializing in solely a small portion of the printed questions. It begs the query of what different inconsistencies may need arisen had the authors shared the entire set of questions and solutions, in addition to the mannequin’s era course of.
It’s evident that the declare of GPT-4 reaching a flawless 100% accuracy is deceptive. The unique work needs to be approached with warning and never be taken as a definitive end result.
Unveiling Positional Bias and Evaluating Mannequin Rankings
The current development of evaluating fashions, like Vicuna, Koala, and Dolly, has gained recognition, particularly with the emergence of GPT-4, as showcased within the earlier instance. Nevertheless, it’s important to grasp the nuances of such comparisons to acquire correct evaluations.
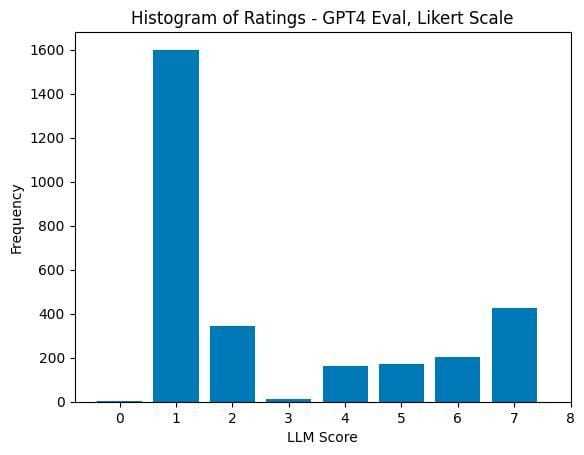
It may appear affordable to imagine that if Fashions A and B are swapped, the scores would stay the identical, with solely the labels inverted. Nevertheless, an intriguing phenomenon known as “positional bias” emerges, the place the mannequin tends to assign greater scores extra regularly to Mannequin A (a ranking of 1). Wanting on the graph, we are able to observe that it needs to be practically symmetrical round 4-5, because the patterns are shuffled randomly. This symmetrical distribution is often achieved when human evaluations are carried out.
However what if we instruct the mannequin to contemplate this positional bias and forestall it from excessively assigning items? This method partially works however leads to a shift within the graph in the other way, though to a lesser extent.
A research performed by the researchers at HuggingFace examined the solutions offered by 4 fashions to 329 totally different questions. The findings provide worthwhile insights, with a number of intriguing observations value highlighting:
Firstly, when evaluating the rankings of the 4 fashions based mostly on pairwise comparisons, the assessments made by GPT-4 and human evaluators aligned. The Elo ranking system revealed differing gaps within the mannequin rankings. This means that whereas the mannequin can distinguish between good and dangerous solutions, it faces challenges in precisely assessing borderline circumstances which are extra much like human evaluations.
GPT-4 tends to fee the solutions of different fashions (educated on GPT-4 solutions) greater than these offered by actual human evaluators. This discrepancy raises questions concerning the mannequin’s capability to precisely gauge the standard of solutions and emphasizes the necessity for cautious consideration.
A excessive correlation (Pearson=0.96) was noticed between the GPT-4 rating and the variety of distinctive tokens within the response. This discovering additional underscores that the mannequin’s analysis doesn’t essentially replicate the standard of the reply. It serves as a reminder to train warning when relying solely on model-based evaluations.
The analysis of fashions requires a nuanced understanding of potential biases and limitations. The presence of positional bias and the variations in rankings spotlight the necessity for a complete method to mannequin assessments.
Exploring Mannequin Analysis Strategies
Of their analysis, the authors employed a collection of strategies in a sequential method. If GPT-4 was unable to reply a query, it was introduced with the three most related examples from the immediate and requested to resolve it. If the mannequin nonetheless couldn’t present a solution, the phrase “suppose step-by-step” was added. And if the mannequin failed once more, they resorted to writing code. Consequently, any questions that GPT-4 answered accurately (in keeping with its personal analysis) weren’t requested once more.
One would possibly argue that this method appears absurd, because it successfully entails analyzing the right solutions. It’s akin to having somebody scrutinize your examination options, declaring them incorrect till they encounter an accurate one, at which level they cease criticizing and also you chorus from making additional modifications. Whereas this technique will not be replicable in real-world manufacturing eventualities because of the absence of a definitive right reply for comparability, it does make clear an fascinating perspective.
From a metric standpoint, this method raises equity considerations. If the mannequin is given even a immediate of criticism for the right reply, whereby it’s requested to search out errors and make corrections, there’s a danger of reworking an accurate determination into an incorrect one. In such a state of affairs, the reply might change, and the result turns into skewed.
Ideally, a complete article would have explored the implications of this method, together with the way it impacts metrics and the influence on total high quality. Sadly, the present article falls brief in these points.
The analysis does provoke thought and contemplation concerning totally different analysis strategies and the notion of validating intermediate steps.
Learn extra about AI:
[ad_2]
Source link


