
[ad_1]
The latest leak of particulars surrounding GPT-4 has despatched shockwaves by the AI group. The leaked info, obtained from an undisclosed supply, gives a glimpse into the awe-inspiring capabilities and unprecedented scale of this groundbreaking mannequin. We’ll break down the information and unveil the important thing facets that make GPT-4 a real technological marvel.

GPT-4’s Large Parameters Rely
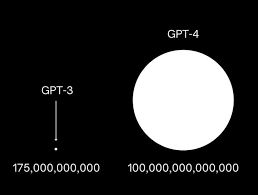
Some of the hanging revelations from the leak is the sheer magnitude of GPT-4. It boasts an astounding dimension, with greater than 10 instances the parameters of its predecessor, GPT-3. It’s estimated to have a staggering whole of roughly 1.8 trillion parameters distributed throughout a powerful 120 layers. This substantial enhance in scale undoubtedly contributes to GPT-4’s enhanced capabilities and potential for groundbreaking developments.
Combination of Specialists Mannequin (MoE)
To make sure affordable prices whereas sustaining distinctive efficiency, OpenAI applied a mix of specialists (MoE) mannequin in GPT-4. By using 16 specialists inside the mannequin, every consisting of round 111 billion parameters for multi-layer perceptrons (MLP), OpenAI successfully optimized useful resource allocation. Notably, throughout every ahead go, solely two specialists are routed, minimizing computational necessities with out compromising outcomes. This progressive strategy demonstrates OpenAI’s dedication to maximizing effectivity and cost-effectiveness of their fashions.
Very fascinating and detailed leak of the GPT-4 structure, with wonderful evaluation of the reasoning behind it and it is implications – by @dylan522p :https://t.co/eHE7VlGY5V
A non-paywalled abstract might be discovered right here: https://t.co/rLxw5s9ZDt
— Jan P. Harries (@jphme) July 11, 2023
Simplified MoE Routing Algorithm
Whereas the mannequin usually explores superior routing algorithms for choosing specialists to deal with every token, OpenAI’s strategy within the present GPT-4 mannequin is reportedly extra simple. The routing algorithm employed by the AI is alleged to be comparatively easy, however nonetheless efficient. Roughly 55 billion shared parameters for consideration facilitate the environment friendly distribution of tokens to the suitable specialists inside the mannequin.
Environment friendly Inference
GPT-4’s inference course of showcases its effectivity and computational prowess. Every ahead go, devoted to producing a single token, makes use of roughly 280 billion parameters and 560 TFLOPs (tera floating-point operations per second). This stands in stark distinction to the immense scale of GPT-4, with its 1.8 trillion parameters and three,700 TFLOPs per ahead go in a purely dense mannequin. The environment friendly use of sources highlights OpenAI’s dedication to reaching optimum efficiency with out extreme computational necessities.
In depth Coaching Dataset
GPT-4 has been educated on a colossal dataset comprising roughly 13 trillion tokens. You will need to word that these tokens embody each distinctive tokens and tokens accounting for epoch numbers. The coaching course of consists of two epochs for text-based information and 4 epochs for code-based information. OpenAI leveraged hundreds of thousands of rows of instruction fine-tuning information sourced from ScaleAI and internally to refine the mannequin’s efficiency.
Refinement by High quality-Tuning from 8K to 32K
The pre-training section of GPT-4 employed an 8k context size. Subsequently, the mannequin underwent fine-tuning, ensuing within the 32k model. This development builds upon the pre-training section, enhancing the mannequin’s capabilities and tailoring it to particular duties.
Scaling with GPUs through Parallelism
OpenAI harnessed the ability of parallelism in GPT-4 to leverage the total potential of their A100 GPUs. They employed 8-way tensor parallelism, which maximizes parallel processing, as it’s the restrict for NVLink. Moreover, 15-way pipeline parallelism was utilized to additional improve efficiency. Whereas particular strategies akin to ZeRo Stage 1 have been possible employed, the precise methodology stays undisclosed.
Coaching Value and Utilization Challenges
Coaching GPT-4 was an intensive and resource-intensive endeavor. OpenAI allotted roughly 25,000 A100 GPUs over a interval of 90 to 100 days, working at a utilization charge of roughly 32% to 36% MFU (most ceaselessly used). The coaching course of incurred quite a few failures, necessitating frequent restarts from checkpoints. If estimated at $1 per A100 hour, the coaching prices for this run alone would quantity to roughly $63 million.
Tradeoffs in Combination of Specialists
Implementing a mix of specialists mannequin presents a number of tradeoffs. Within the case of GPT-4, OpenAI opted for 16 specialists as a substitute of a better quantity. This resolution displays a steadiness between reaching superior loss outcomes and making certain generalizability throughout varied duties. Extra specialists can current challenges when it comes to job generalization and convergence. OpenAI’s option to train warning in skilled choice aligns with their dedication to dependable and sturdy efficiency.
Inference Value
In comparison with its predecessor, the 175 billion parameter Davinci mannequin, GPT-4’s inference price is roughly 3 times increased. This discrepancy might be attributed to a number of components, together with the bigger clusters required to assist GPT-4 and the decrease utilization achieved throughout inference. Estimations point out an approximate price of $0.0049 cents per 1,000 tokens for 128 A100 GPUs, and $0.0021 cents per 1,000 tokens for 128 H100 GPUs when inferring GPT-4 with an 8k. These figures assume first rate utilization and excessive batch sizes, essential concerns for price optimization.
Multi-Question Consideration
OpenAI leverages multi-query consideration (MQA), a way broadly employed within the subject, in GPT-4 as properly. By implementing MQA, the mannequin requires just one head, considerably lowering the reminiscence capability needed for the key-value cache (KV cache). Regardless of this optimization, it ought to be famous that the 32k batch GPT-4 can’t be accommodated on 40GB A100 GPUs, and the 8k is constrained by the utmost batch dimension.
Steady Batching
To strike a steadiness between latency and inference prices, OpenAI incorporates each variable batch sizes and steady batching in GPT-4. This adaptive strategy permits for versatile and environment friendly processing, optimizing useful resource utilization and lowering computational overhead.
Imaginative and prescient Multi-Modal
GPT-4 introduces a separate imaginative and prescient encoder alongside the textual content encoder, that includes cross-attention between the 2. This structure, harking back to Flamingo, provides further parameters to the already spectacular 1.8 trillion parameter depend of GPT-4. The imaginative and prescient mannequin undergoes separate fine-tuning utilizing roughly 2 trillion tokens following the text-only pre-training section. This imaginative and prescient functionality empowers autonomous brokers to learn internet pages, transcribe pictures, and interpret video content material—a useful asset within the age of multimedia information.
Speculative Decoding
An fascinating facet of GPT-4’s inference technique is the potential use of speculative decoding. This strategy entails using a smaller, quicker mannequin to generate predictions for a number of tokens prematurely. These predicted tokens are then fed into a bigger “oracle” mannequin as a single batch. If the smaller mannequin’s predictions align with the bigger mannequin’s settlement, a number of tokens might be decoded collectively. Nevertheless, if the bigger mannequin rejects the tokens predicted by the draft mannequin, the remainder of the batch is discarded, and inference continues solely with the bigger mannequin. This strategy permits for environment friendly decoding whereas probably accepting decrease likelihood sequences. It’s price noting that this hypothesis stays unverified at the moment.
Inference Structure
GPT-4’s inference course of operates on a cluster of 128 GPUs, distributed throughout a number of information facilities in numerous places. This infrastructure employs 8-way tensor parallelism and 16-way pipeline parallelism to maximise computational effectivity. Every node, comprising 8 GPUs, accommodates roughly 130 billion parameters. With a mannequin dimension of 120 layers, GPT-4 can match inside 15 completely different nodes, presumably with fewer layers within the first node because of the must compute embeddings. These architectural selections facilitate high-performance inference, demonstrating OpenAI’s dedication to pushing the boundaries of computational effectivity.
Dataset Measurement and Composition
GPT-4 was educated on a powerful 13 trillion tokens, offering it with an intensive corpus of textual content to be taught from. Nevertheless, not all tokens might be accounted for by the identified datasets used throughout coaching. Whereas datasets like CommonCrawl and RefinedWeb contribute a good portion of the coaching information, there stays a portion of tokens which are unaccounted for, also known as the “secret” information.
Rumours and Speculations
Speculations have emerged relating to the origin of this undisclosed information. One rumor means that it consists of content material from standard platforms akin to Twitter, Reddit, and YouTube, highlighting the potential affect of user-generated content material in shaping GPT-4’s information base. Moreover, there are conjectures surrounding the inclusion of expansive collections like LibGen, a repository of hundreds of thousands of books, and Sci-Hub, a platform offering entry to quite a few scientific papers. The notion that GPT-4 was educated on the whole lot of GitHub has additionally circulated amongst AI fans.
The Reporter’s Opinion
Though there are lots of rumors, you will need to strategy these rumors with warning. The coaching of GPT-4 could have benefited vastly from a particular dataset made up of school textbooks. This dataset, which covers a variety of programs and topics, might have been painstakingly assembled by hand. Faculty textbooks present a structured and complete information base that may be efficiently used to coach a language mannequin and are simply convertible to textual content recordsdata. The inclusion of such a dataset would possibly give the impression that GPT-4 is educated in a wide range of fields.
The Fascination with GPT-4’s Information
One intriguing facet of GPT-4’s coaching is its capability to exhibit familiarity with particular books and even recall distinctive identifiers from platforms like Challenge Euler. Researchers have tried to extract memorized sections of books from GPT-4 to realize insights into its coaching, additional fueling curiosity in regards to the mannequin’s inside workings. These discoveries spotlight the astonishing capability of GPT-4 to retain info and underscore the spectacular capabilities of large-scale language fashions.
The Versatility of GPT-4
The broad spectrum of matters and fields that GPT-4 can seemingly interact with showcases its versatility. Whether or not it’s answering complicated questions in pc science or delving into philosophical debates, GPT-4’s coaching on a various dataset equips it to interact with customers from varied domains. This versatility stems from its publicity to an enormous array of textual sources, making it a beneficial software for a variety of customers.
Learn extra about AI:
[ad_2]
Source link


